The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(patchwork)library(ggplot2)library(ggpubr)# install neuroUp package from CRAN# install.packages("neuroUp")# load neuroUplibrary(neuroUp)
Set seed and create Figure 1a for the Feedback task DLPFC ROI:
In [2]:
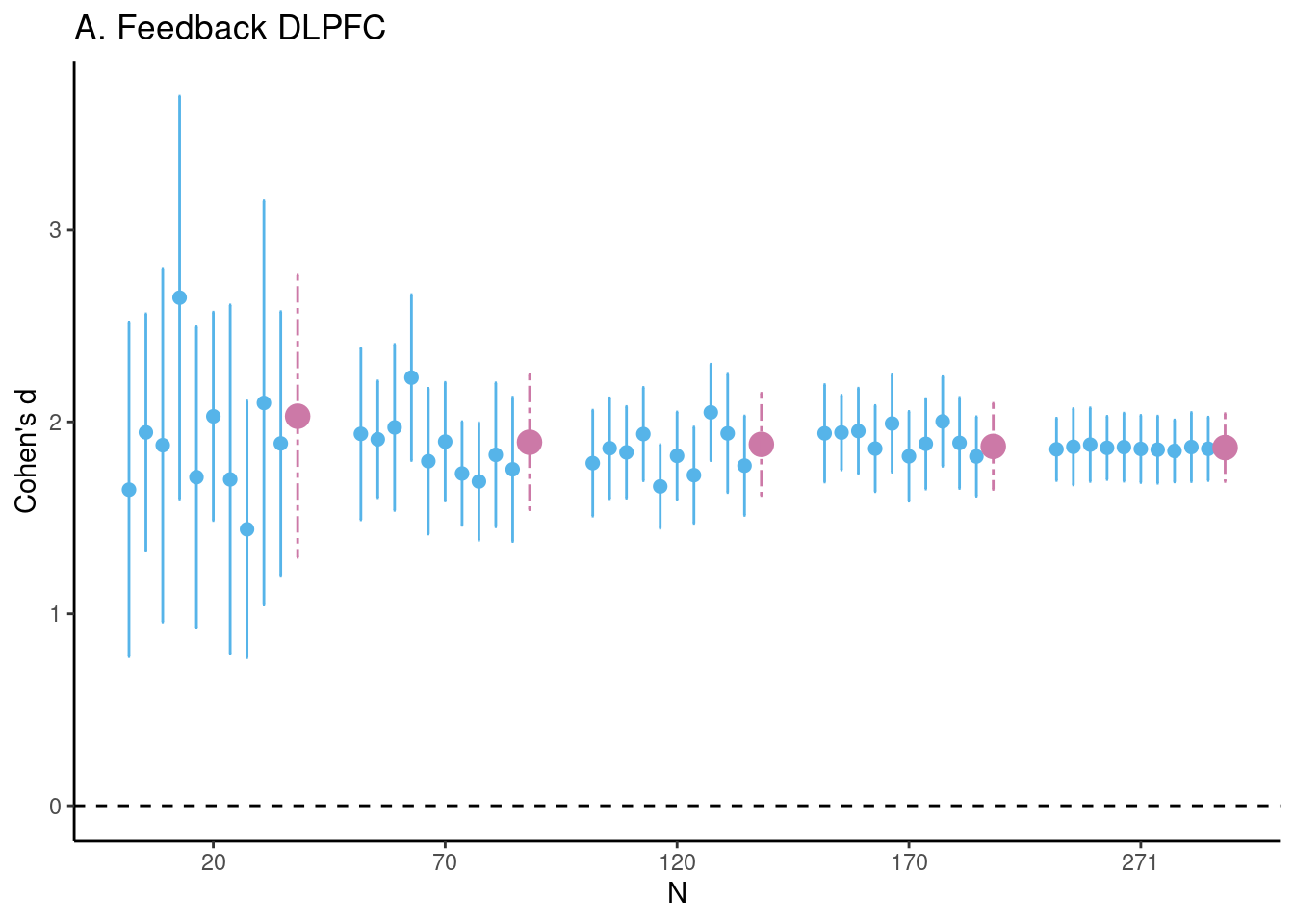
# set seedset.seed(1234)# Estimate differences (unstandardized and Cohen's d)feedback_fig <-estim_diff(data = feedback,vars_of_interest =c("mfg_learning","mfg_application"),sample_size =20:271, k =1000, name ="A. Feedback DLPFC")# plot figure 1a (and remove legend using ggplot2)feedback_fig$fig_cohens_d +theme(legend.position ="none")
Plot Figure 2a for the Feedback task DLPFC ROI:
In [3]:
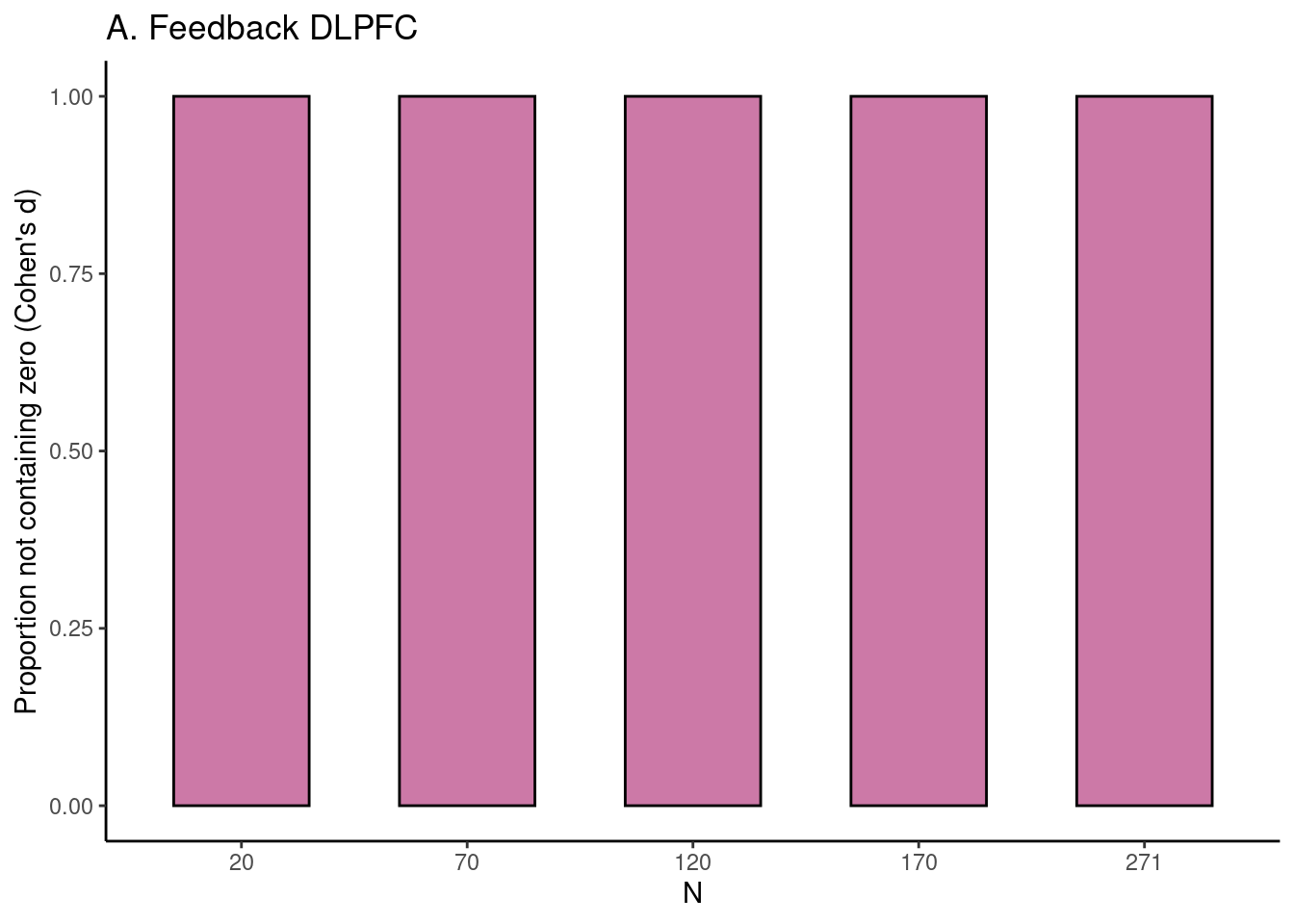
# plot figure 2afeedback_fig$fig_d_nozero
Set seed and create Figure 1b for the Gambling task NAcc ROI:
In [4]:
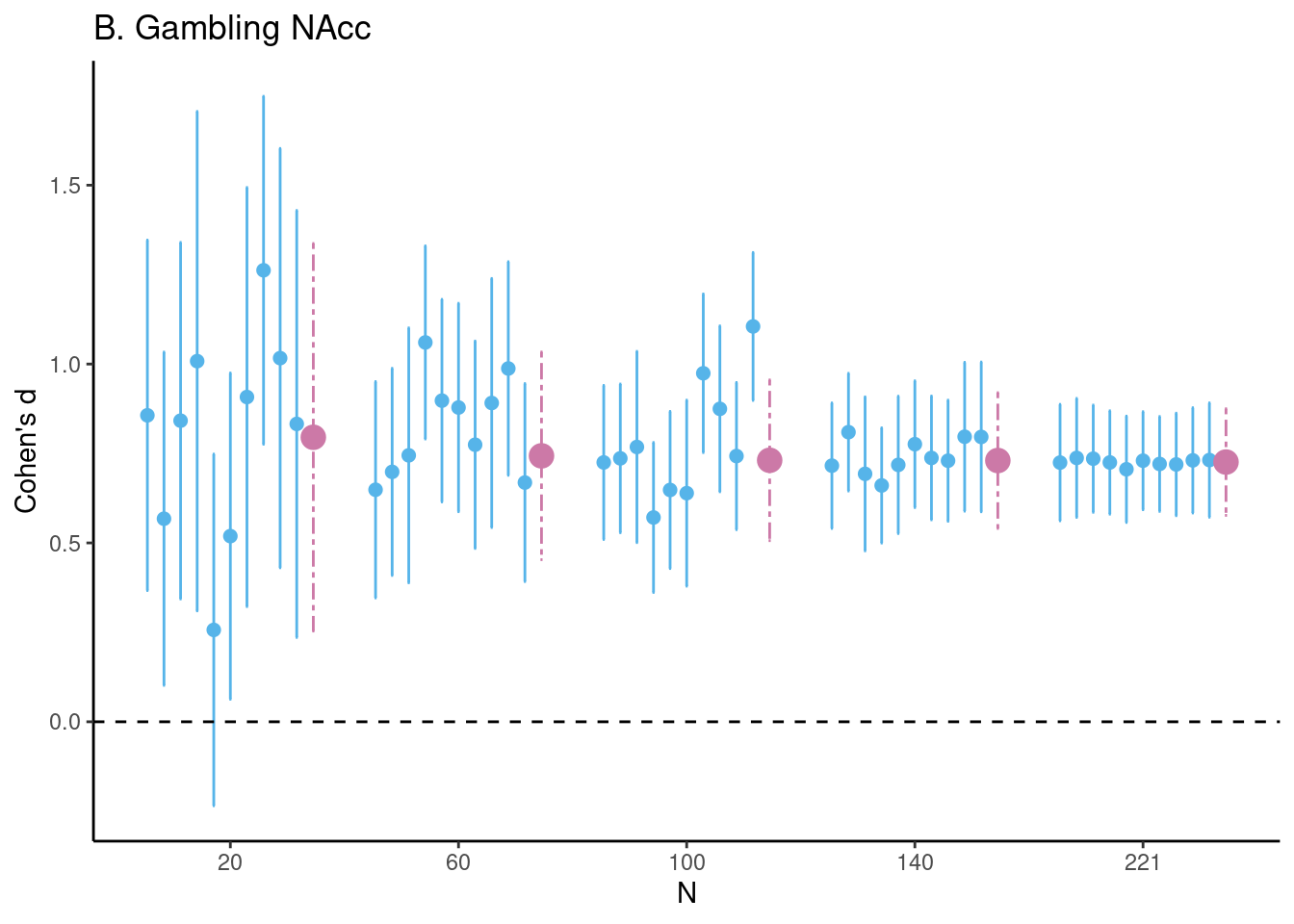
# set seedset.seed(1234)# Estimate differences (unstandardized and Cohen's d)gambling_fig <-estim_diff(data = gambling, vars_of_interest =c("lnacc_self_win", "lnacc_self_loss"), sample_size =20:221, k =1000, name ="B. Gambling NAcc")# plot figure 1b (and remove legend using ggplot2)gambling_fig$fig_cohens_d +theme(legend.position ="none")
Plot Figure 2b for the Gambling task NAcc ROI:
In [5]:
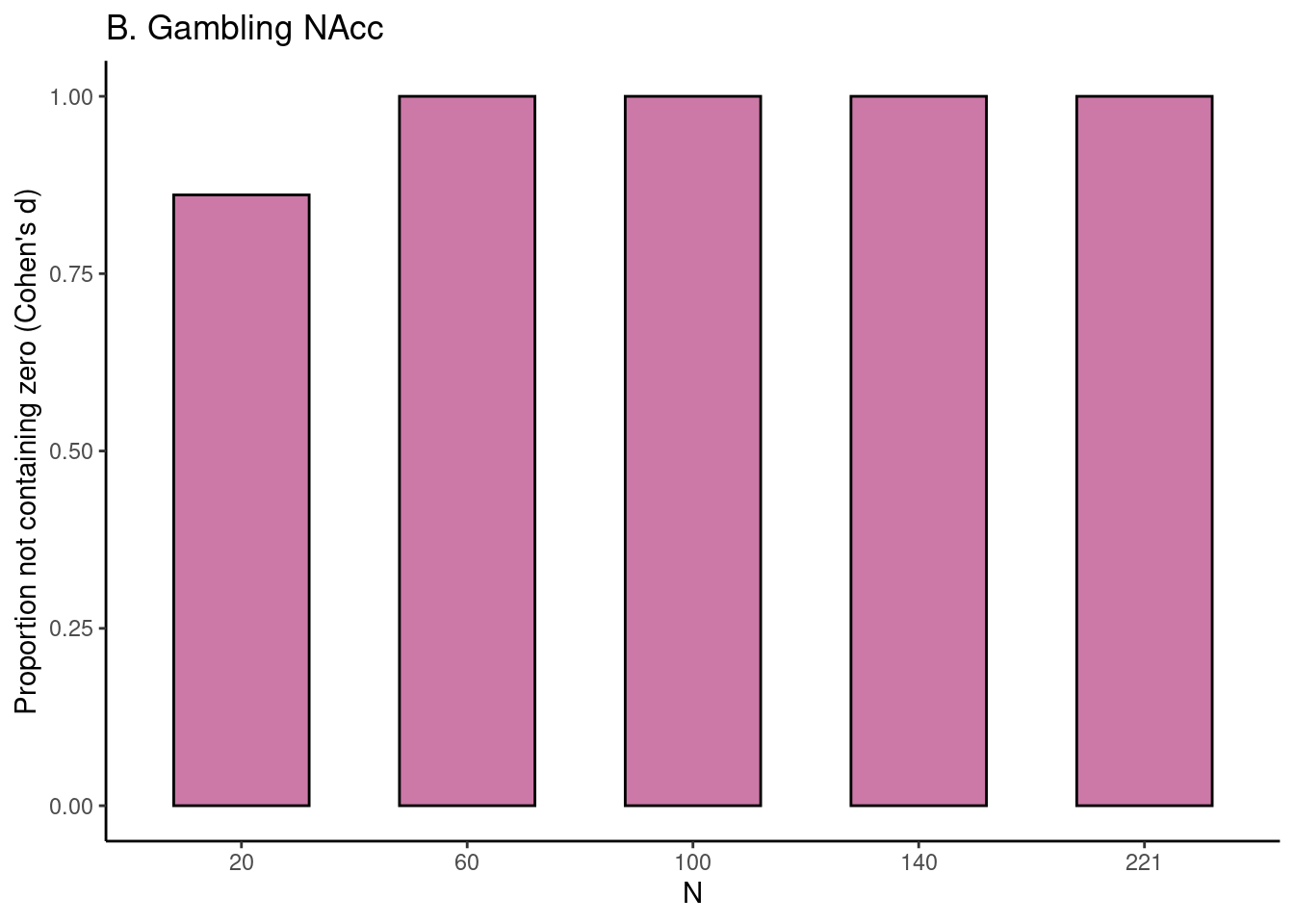
# plot figure 2bgambling_fig$fig_d_nozero
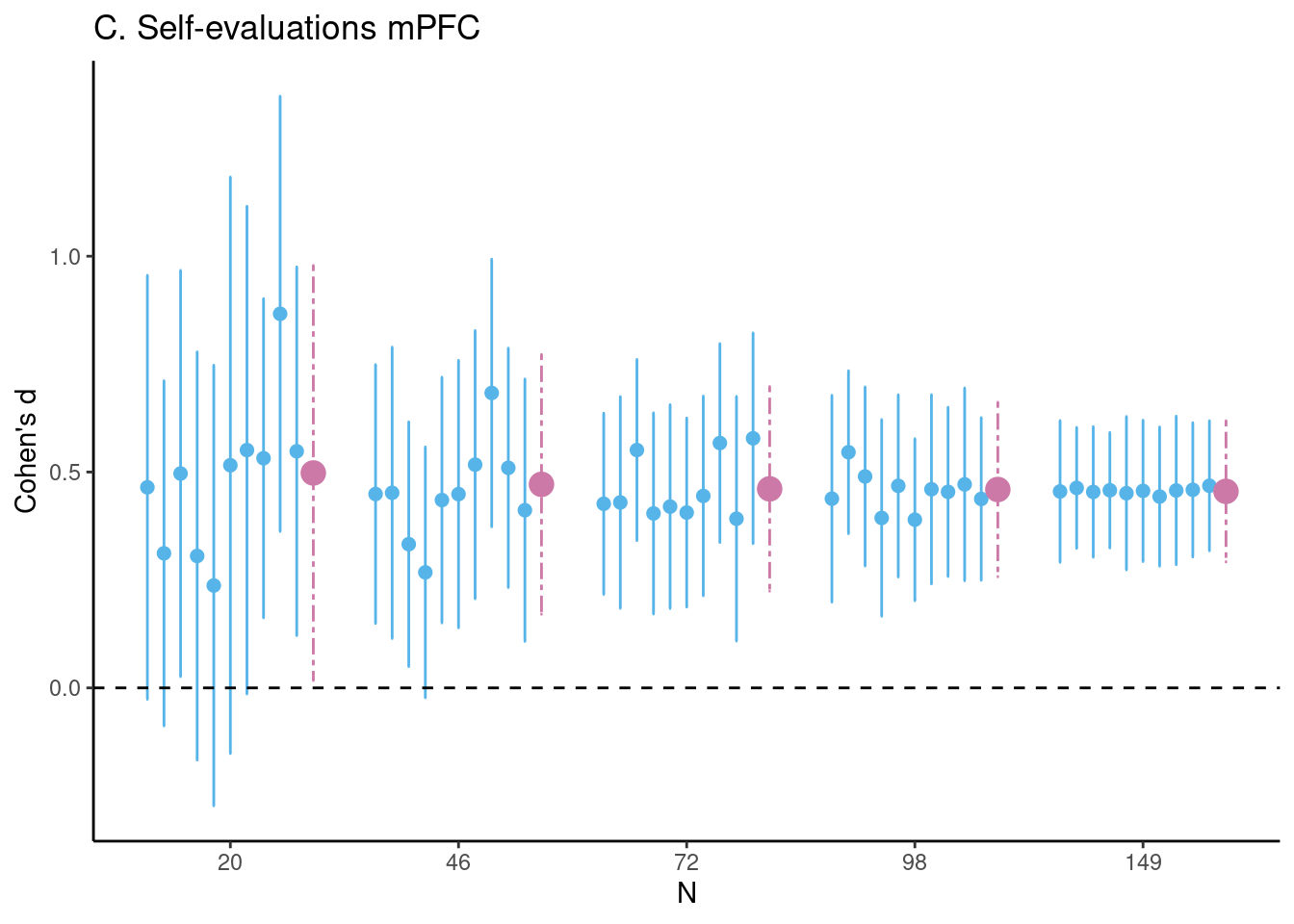
Set seed and create Figure 1c for the Self-evaluations task mPFC ROI:
In [6]:
# set seedset.seed(1234)# Estimate differences (unstandardized and Cohen's d)selfeval_fig <-estim_diff(data = self_eval, vars_of_interest =c("mpfc_self", "mpfc_control"),sample_size =20:149, k =1000, name ="C. Self-evaluations mPFC")# plot figure 1c (and remove legend using ggplot2)selfeval_fig$fig_cohens_d +theme(legend.position ="none")
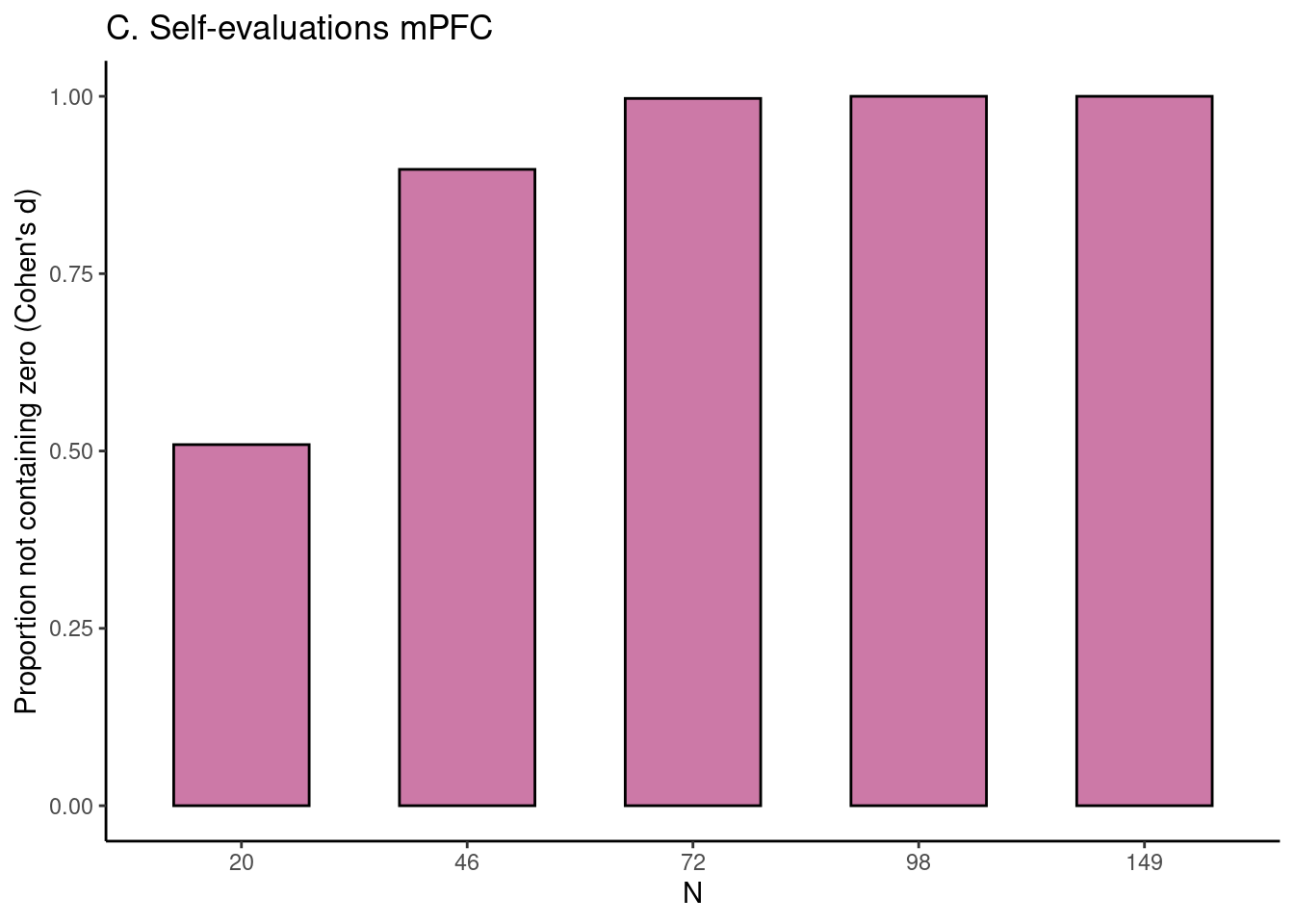
Plot Figure 2c for the Self-evaluations task mPFC ROI:
In [7]:
# plot figure 2cselfeval_fig$fig_d_nozero
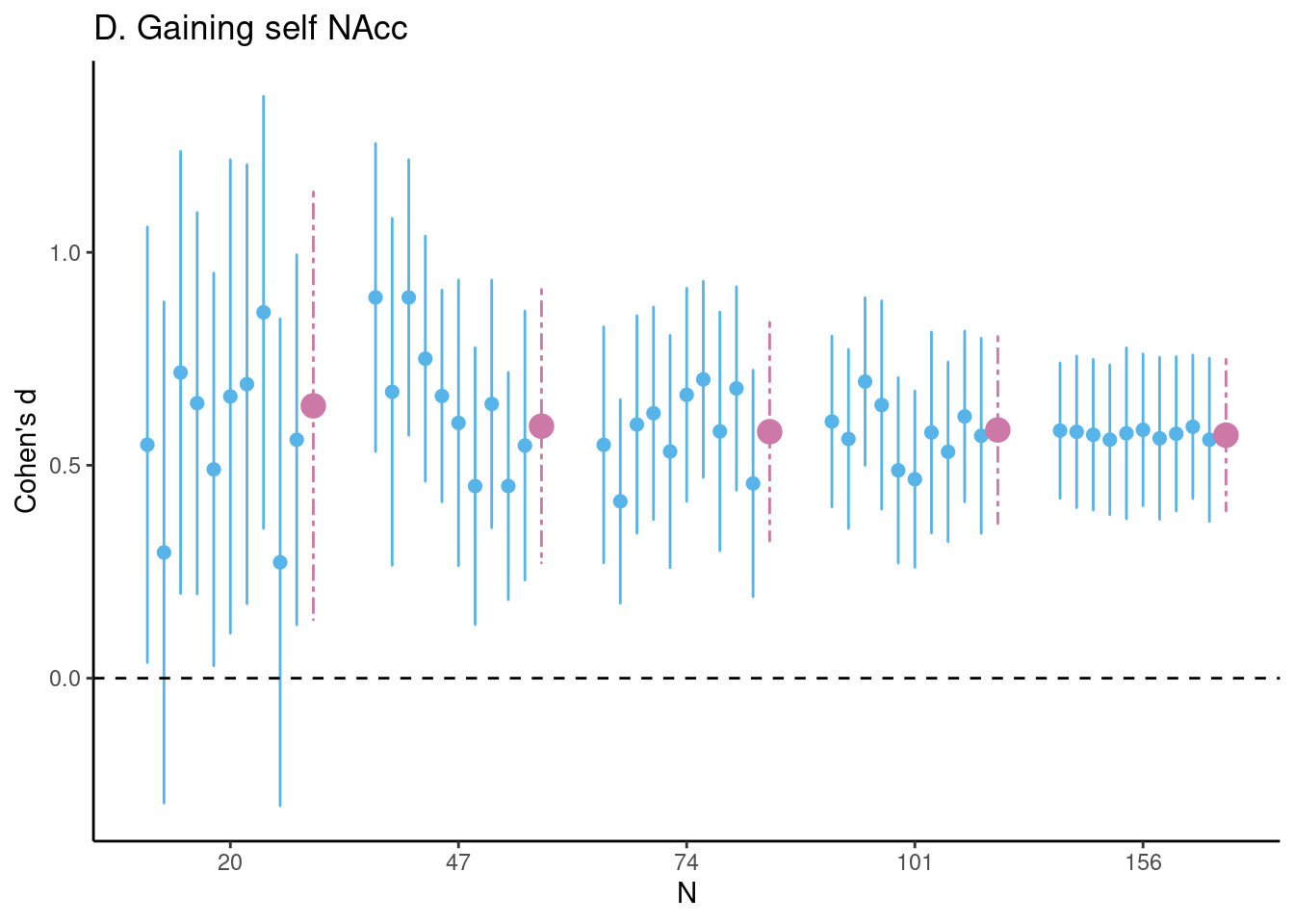
Set seed and create Figure 1d for the Gaining for self task NAcc ROI:
In [8]:
# set seedset.seed(1234)# Estimate differences (unstandardized and Cohen's d)vicar_char_fig <-estim_diff(data = vicar_char, vars_of_interest =c("nacc_selfgain", "nacc_bothnogain"),sample_size =20:156, k =1000, name ="D. Gaining self NAcc")# plot figure 1d (and remove legend using ggplot2)vicar_char_fig$fig_cohens_d +theme(legend.position ="none")
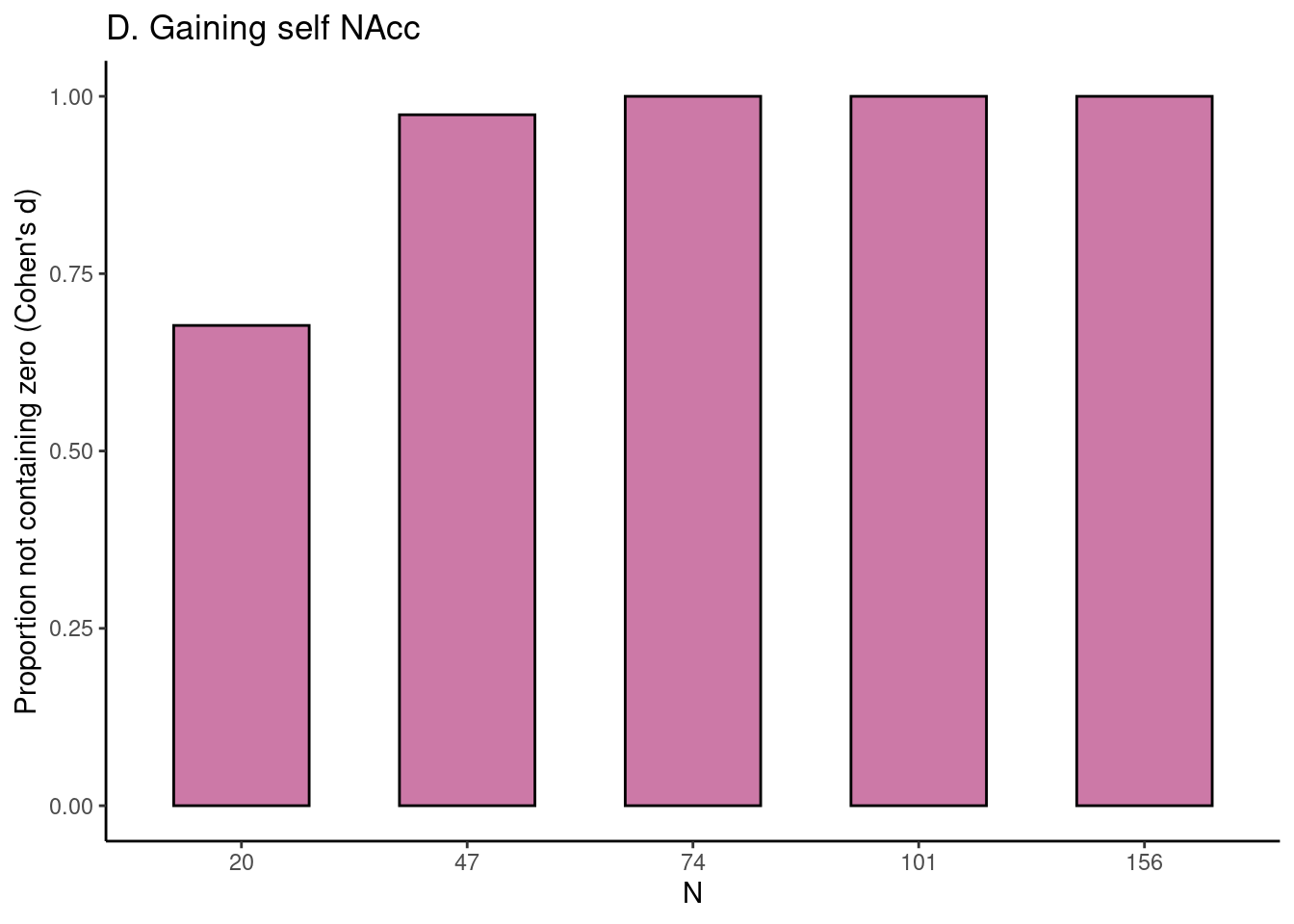
Plot Figure 2d for the Gaining for self task NAcc ROI:
In [9]:
# plot figure 2dvicar_char_fig$fig_d_nozero
Plot a mock figure with similar aesthetics to create an overall ggplot legend.
The only purpose of this code chunk is to make a simple overall legend to show that in light blue a subset of the individual permutations is shown and in purple the overall values. The original legends with permutation numbers will not be shown in the overall figure to create a cleaner look. The approach taken here was to use a simple mock ggplot figure and then use the ggpubr package to isolate the legend and display the legend together with the 4 actual plots.
In [10]:
# make simple mock data to create overall legendlegend_data <-tibble(legend =c("10 permutations","Overall"), N =1:2, scores =c(1.6, 1.8),lower =c(.4, .6), upper =c(2.8, 3))# factorize legend and Nlegend_data$legend <-factor(legend_data$legend)legend_data$N <-as.factor(legend_data$N)# plot data to produce legendfigure_legend <- ggplot2::ggplot(data = legend_data, ggplot2::aes(x = .data$N, y = .data$scores,colour = .data$legend,size = .data$legend) ) + ggplot2::theme_classic() + ggplot2::geom_point(position = ggplot2::position_dodge(.8), ggplot2::aes(x = .data$N, y = .data$scores,colour = .data$legend,size = .data$legend)) + ggplot2::scale_size_manual(values =c(2, 4)) + ggplot2::geom_errorbar(ggplot2::aes(ymin = .data$lower, ymax = .data$upper),linewidth = .5, position = ggplot2::position_dodge(.1)) + ggplot2::scale_linetype_manual(values =c(1, 6)) + ggplot2::scale_color_manual(values =c("#56B4E9","#CC79A7") ) +theme(legend.title=element_blank())# use ggpubr get_legend to plot legend onlyleg <- ggpubr::get_legend(figure_legend)
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
simple_legend <- ggpubr::as_ggplot(leg)# show the simple overall legendsimple_legend
Plot Figure 1 (4 data sets combined):
In [11]:
# plot figure 1 using patchwork libraryfeedback_fig$fig_cohens_d +theme(legend.position ="none") + gambling_fig$fig_cohens_d +theme(legend.position ="none") + selfeval_fig$fig_cohens_d +theme(legend.position ="none") + vicar_char_fig$fig_cohens_d +theme(legend.position ="none") +inset_element(simple_legend, left =1.7, bottom =3.8, right =0, top =0, on_top = T, align_to ='full')
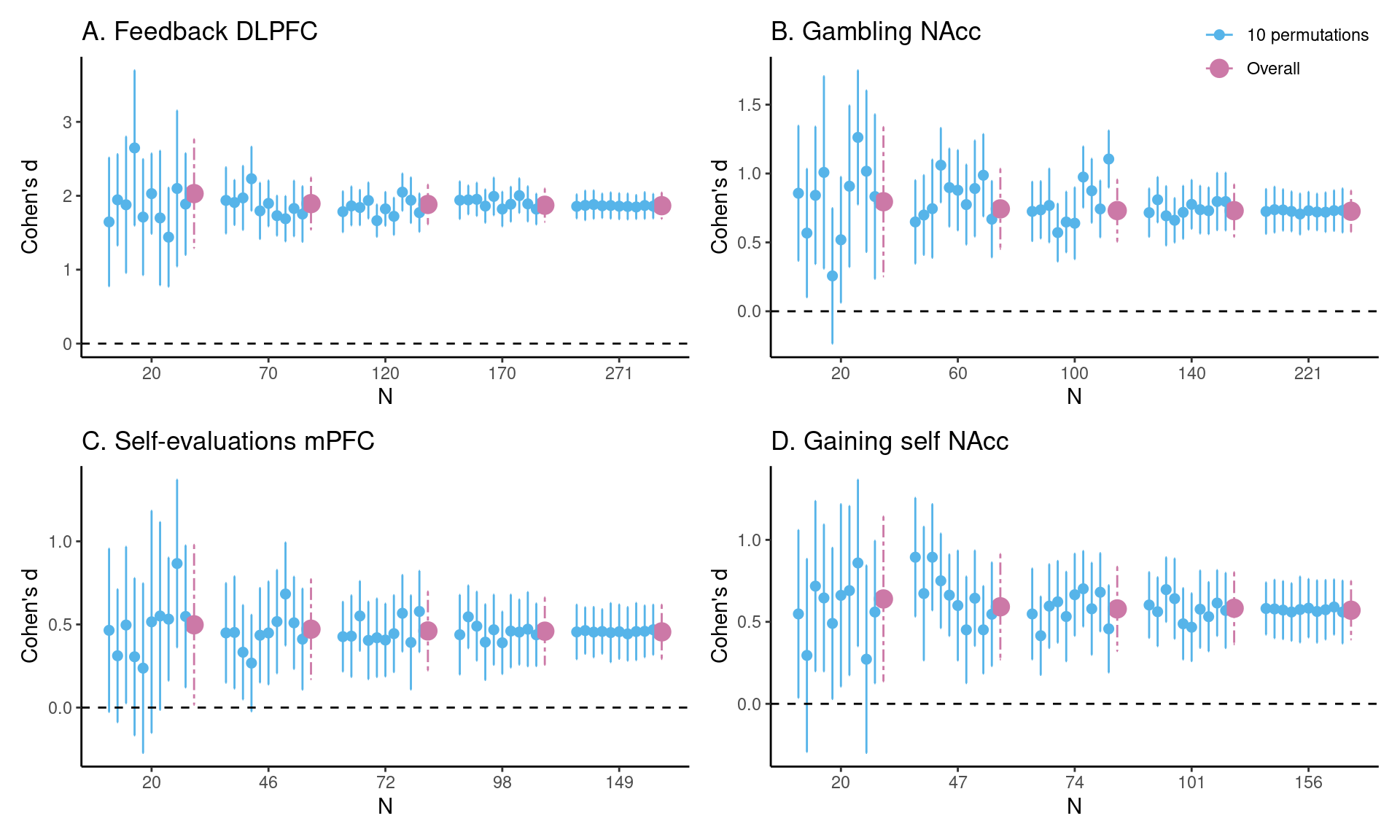
Estimates of task effects for five different sample sizes (starting with \(N = 20\), then 1/5th parts of the total dataset). For each sample size 10 randomly chosen HDCI’s out of the 1000 HDCI’s computed are displayed (in light blue). The average estimate with credible interval summarizing the 1000 HDCI’s for each sample size are plotted in reddish purple. DLPFC = dorsolateral prefrontal cortex; mPFC = medial prefrontal cortex; NAcc = nucleus accumbens.
Plot Figure 2 (4 data sets combined):
In [12]:
# plot figure 2 using patchwork libraryfeedback_fig$fig_d_nozero +ylab(label ="Proportion not containing zero") + gambling_fig$fig_d_nozero +ylab(label ="Proportion not containing zero") + selfeval_fig$fig_d_nozero +ylab(label ="Proportion not containing zero") + vicar_char_fig$fig_d_nozero +ylab(label ="Proportion not containing zero")
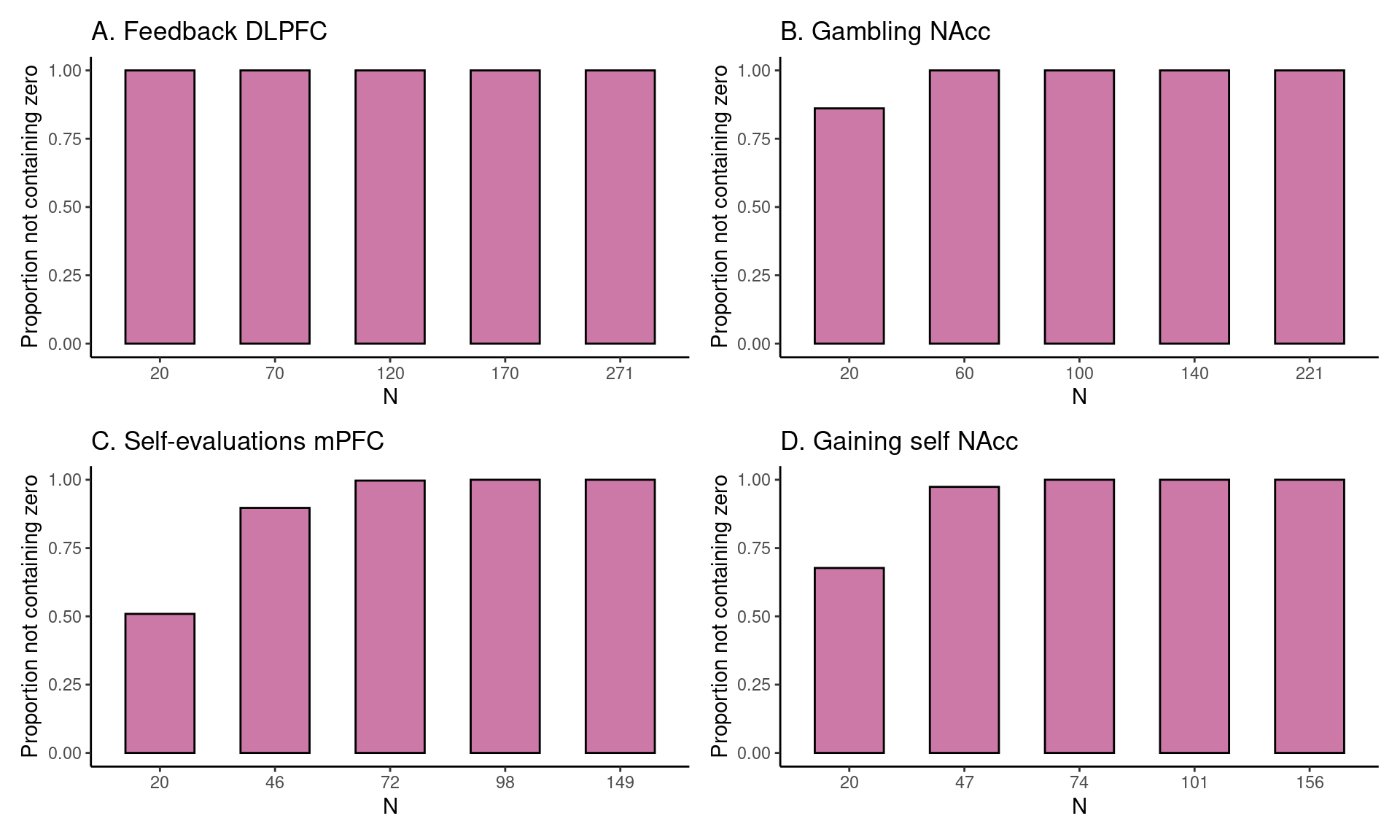
For each task, for five different sample sizes (starting with \(N = 20\), then 1/5th parts of the total dataset), the proportion of intervals not containing the value 0 is plotted in reddish purple.
Extract numbers to make table 2:
In [13]:
# first extract tibble from results (select mean only)feedback_sum <-as_tibble(feedback_fig$tbl_select) %>% dplyr::filter(permutation =="Overall")gambling_sum <-as_tibble(gambling_fig$tbl_select) %>% dplyr::filter(permutation =="Overall")selfeval_sum <-as_tibble(selfeval_fig$tbl_select) %>% dplyr::filter(permutation =="Overall")gaining_sum <-as_tibble(vicar_char_fig$tbl_select) %>% dplyr::filter(permutation =="Overall")